Table Partitioning
You should default to non-partitioned tables for most use cases when working with Delta Lake.
- Most Delta Lake tables, especially small-to-medium sized data, will not benefit from partitioning.
- Because partitioning physically separates data files, this approach can result in a small files problem and prevent file compaction, and efficient data skipping.
- The benefits observed in Hive or HDFS do not translate to Delta Lake, and you should consult with an experienced Delta Lake architect before partitioning tables.
Table Cloning
Table Cloning is a great way to setup tables for testing SQL code while still in development.
DEEP CLONE. Copy table metadata + data files.- Rerun the command will sync changes from the source to target location.
SHALLOW CLONE. Just copy table metadata.
Table Overwriting
We could use CREATE OR REPLACE AS SELECT (CRAS) statements to Complete Overwrites Delta Lake Tables have multiple benefits instead of deleting and recreating tables:
- Overwriting a table is much faster because it doesn’t need to list the directory recursively or delete all files.
- The old version of the table still exists, and it can easily retrieve the old data using Time Travel.
- It’s an atomic operation, meaning concurrent queries can still read the table while you are deleting the table.
- Due to ACID transaction guarantees, if overwriting the table fails the table will automatically roll back to its previous state.
INSERT OVERWRITE provides a nearly identical outcome as Complete Overwrite , but is a more “safer” technique for overwriting an existing table, because
- It can only overwrite an existing table, not create a new one like CRAS statement
- It can only overwrite with new records that match the current table schema, this can help us prevent disrupting downstream consumers
- It can overwrite individual partitions.
Performance Optimisation
OPTIMIZE
Delta Lake can improve the speed of read queries from a table. One way to improve this speed is by compacting small files into large ones. You trigger compaction by running the OPTIMIZE command.
VACUUM
Another way is to use VACUUM command to automatically clean up stale files. By default, VACUUM will prevent you from deleting files less than 7 days old, just to ensure that no long-running operations are still referencing any of the files to be deleted. But you can configure Delta Lake with following knobs to enable deleting files less than 7 days.
Delta Live Table
Create a Silver Table from a Bronze Table
In Delta Live Table, you can stream data from other tables in the same pipeline by using the STREAM() function. In this case, we must define a streaming live table using CREATE STREAMING LIVE TABLE statement. Remember to query another LIVE table, we ust always use the LIVE keyword to the table name.
| |
Data Ingestion
Multiple Data Source
If we have scenarios where we need to ingest data from multiple tables, we could continue to use the MERGE INTO operation, but tweak it for Insert-Only Merge for Deduplication.
This optimised command uses the same MERGE INTO syntax but only provide a WHEN NOT MATCHED clause.
Below we use this to confirm that records with the same user_id and event_timestamp aren’t already in the events table.
| |
Single Data Source
COPY INTO command is a good friend for incrementally ingesting data from external system. It’s an idempotent option, and potentially
Data Quality
Quality Enforcement with CONSTRAINT
We can specify certain column-level constraints in Databricks,
For example,
| |
ADD CONSTRAINT command will verifies that all existing rows satisfy the constraint before adding it to the table.
General
GLOBAL TEMP VIEW
If there are some relational object that must be used and shared with other data engineers in other sessions on the same cluster. In order to save on storage cost, avoiding copying and storing physical data, the best option to resolve this problem is to use GLOBAL TEMP VIEW in Databricks.
CREATE TABLE USING
When we use CREATE TABLE statement, we can also specify particular data source options. The following are all the data sources that supported by Databricks
- TEXT
- AVRO
- BINARYFILE
- CSV
- JSON
- PARQUET
- ORC
- DELTA
The following additional file formats to use for the table are supported in the Databricks Runtime
- JDBC
- LIBSVM
- a fully-qualified class name of a custom implementation of
org.apache.spark.sql.sources.DataSourceRegister.
The default option is DELTA. For any data_source other than DELTA you must also specify a LOCATION unless the table catalog is hive_metastore.
Auto Loader VS COPY INTO
There are several things to consider when choosing between Auto Loader and COPY INTO command:
- Volumes of Data. If you are going to ingest files in the order of thousands, you can use COPY INTO command. If you are expecting files in the order of millions or more over time, the use Auto Loader.
- If your data schema is going to evolve frequently, Auto Loader provides better primitives around schema inference and evolution.
- Loading a subset of re-uploaded files can be a bit easier to manage with COPY INTO. With Auto Loader, it’s harder to reprocess a select subsets of files. However, you can use COPY INTO to reload the subset of files while an Auto Loader stream is running simultaneously.
SCD Type 2 Table
| |
| |
| |
Change Data Capture (CDC) feed
We can use MERGE INTO command to process a CDC feed. MERGE INTO command allows you to merge a set of updates, insertions and deletions based on a source table into a target delta table.
| |
However, Merge operations cannot be performed if multiple source rows matched and attempted to modify the same target row in the delta table.
CDC feed with multiple updates for the same key will generate an exception.
To avoid this error, you need to ensure that you are merging only the most recent changes. We can use the rank() over (window) function to achieve that. What we need to do is to just filter out the records that rank=1, and merge them into our target table using MERGE INTO COMMAND.
Change Data Feed (CDF)
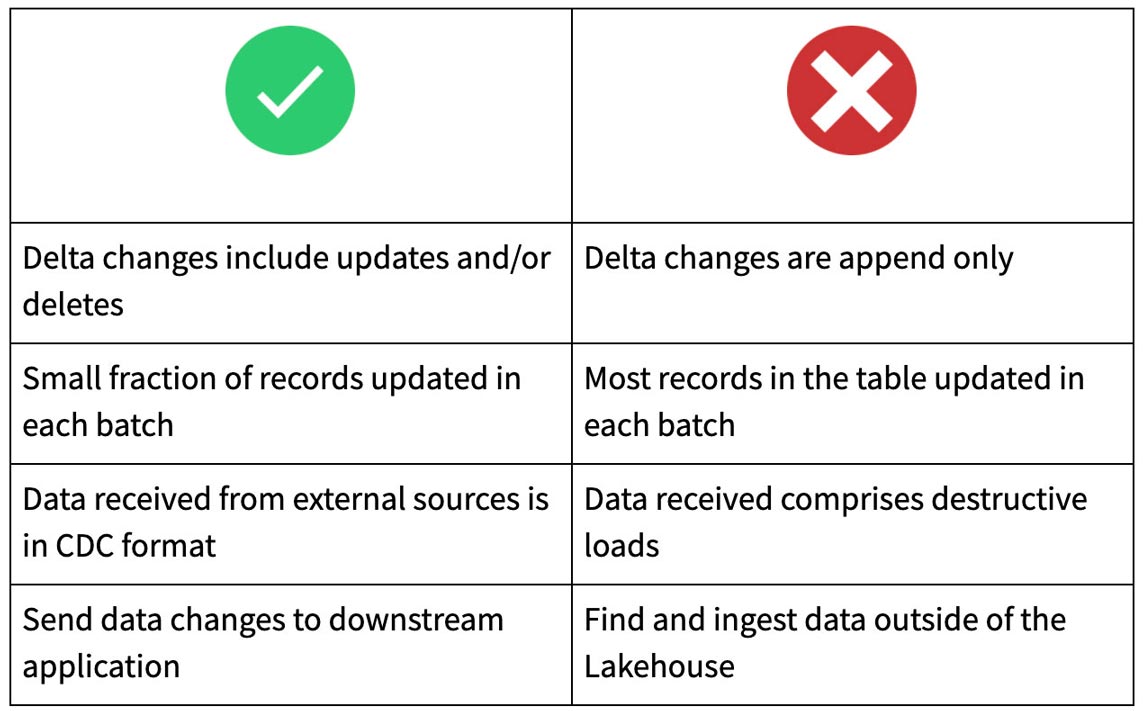
Generally speaking, we use CDF for sending incremental data changes to downstream tables in a multi-hop architecture. So use CDF when only small fraction of records updated in each batch. Such updates are usually received from external sources in CDC format.
If most of the records in the table are updated, or if the table is overwritten in each batch, then don’t use CDF.
When to use Change Data Feed
Dynamic View
Dynamics views allow identity ACL access control list to be applied to data in a table at the column or row level. So user with sufficient privileges will be able to see all the fields, while restricted users will be shown arbitrary results as defined at view creation.
Column level control
| |
Row level control
| |
See here for more details.
Structured Streaming
In order to restart streaming queries on failure, it’s recommended to configure Structured Streaming jobs with the following job configuration
- Retries: Set to Unlimited
- Maximum concurrent runs: Set to 1. There must be only one instance of each query concurrently active.
- Clusters: Set this always to use a new job cluster and use the latest Spark version (or at least version 2.1)
- Notifications: Set this if you want email notification on failures
- Schedule: Do not set a schedule
- Timeout: Do not set a timeout. Streaming queries run for an indefinitely long time.
Streaming query to handle late-arriving data
pyspark.sql.DataFrame.withWaterMark
| |
Streaming query to calculate business-level aggregation for each non-overlapping five-minute interval.
| |
pyspark.sql.functions.window
Global Spark Configuration
| |