00 - General
01 - Databricks Workspace and Services
Databricks Architecture and Services
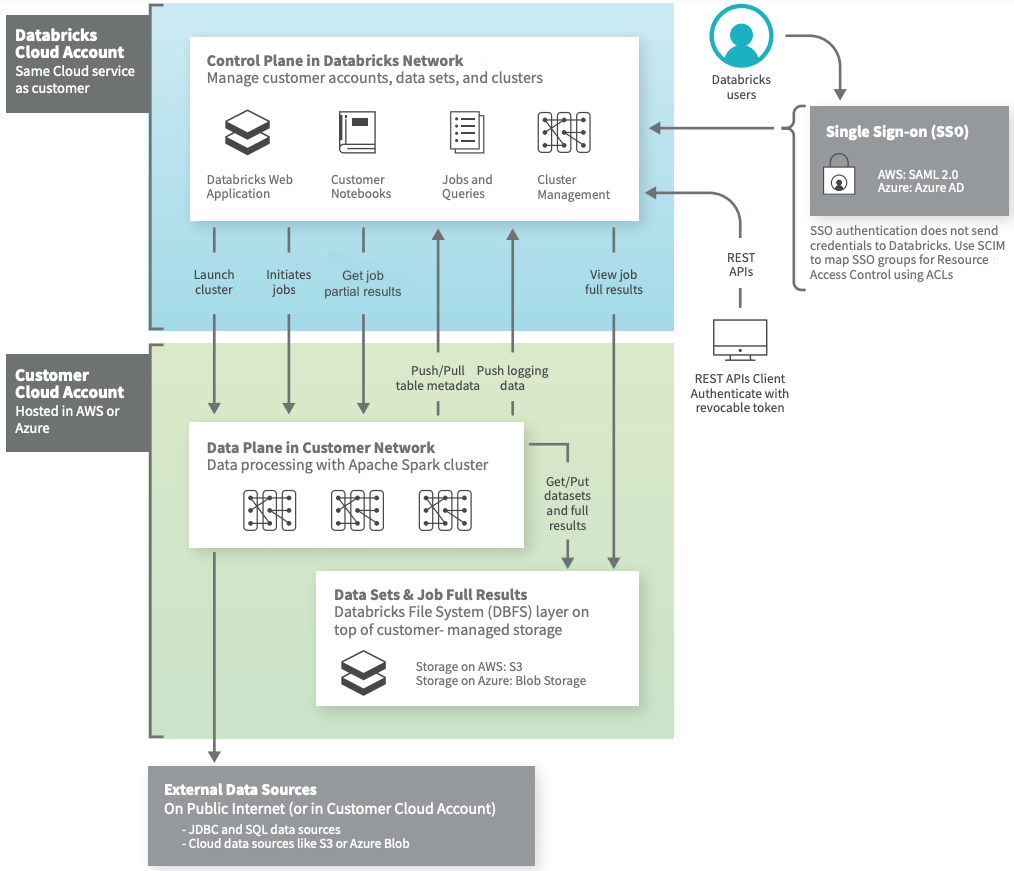
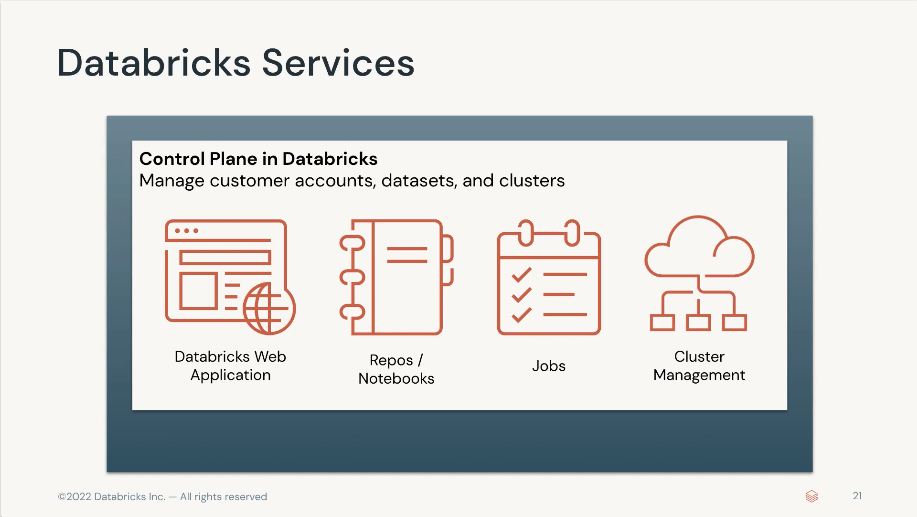
Databricks Control Plane
- Web Application
- Databricks SQL
- Databricks Machine Learning
- Databricks Data Science and Engineering
- Repos / Notebooks
- Job Scheduling
- Cluster Management
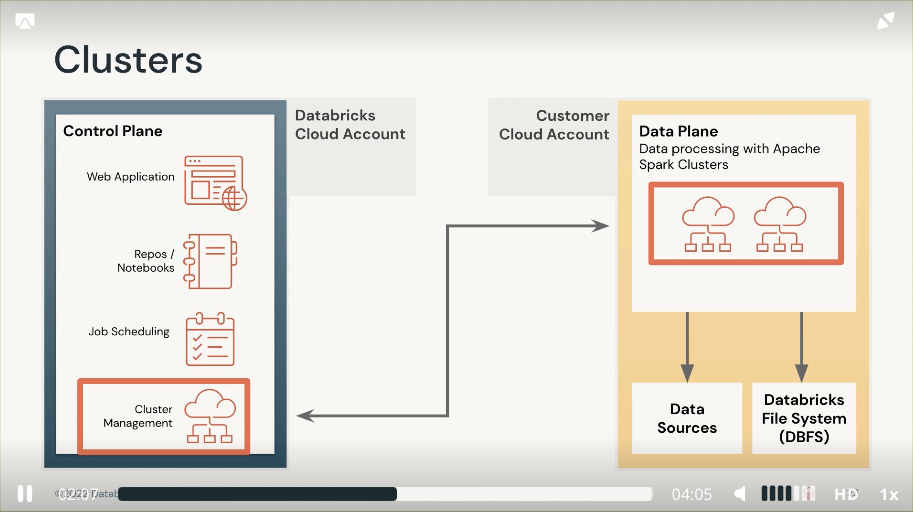
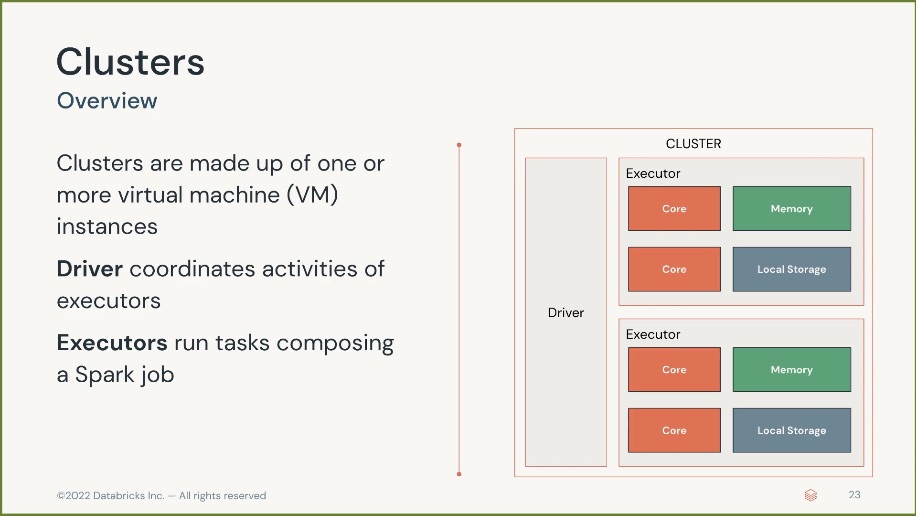
Cluster
Cluster are made up of one or more virtual machine (VMs) instances
- Driver node. Coordinate activities of executors, aka master node in EMR.
- Executor node. Run tasks composing a Spark job, aka run node in EMR.
Clusters Type
- All-purpose Clusters
- Analyse data collaboratively using interactive notebooks
- Create clusters from the Workspace or API
- It can be shared with multiple people to do collaborative work
- Configuration info retains up to 70 clusters for up to 30 days
- Job Clusters
- Run automated jobs
- The Databricks job scheduler creates new job clusters when running jobs, and terminate job clusters when complete
- You cannot restart a job cluster, because job clusters are provisioned in isolated, parameterised environment
- Configuration info retain up to 30 clusters
Notebook Basics
Magic Command
%python. Run python code in a cell.%sql. Run sql code in a cell.%md. Run Markdown syntax code in a cell.%run. Run an executable or another notebook within a notebook.
Keyboard Shortcut
General:
h. Help window.esc. Switch to Command mode.⌘Command+A. Select all cells.
Cell Operation in Edit Mode
⇧Shift+↩Enter. Run command and move to next cell.⌥Option+↩Enter. Run command and insert new cell below⌘Command+]/[. Indent/Unindent selection.^Control+⌥Option+P. Insert a cell above.^Control+⌥Option+N. Insert a cell below.^Control+⌥Option+-. Split a cell at current cursor.^Control+⌥Option+D. Delete current cell.^Control+⌥Option+↑Up. Move a cell up.^Control+⌥Option+↓Down. Move a cell down.
Cell Operation in Command Mode
⌘Command+⇧ Shift+F. Format a cell.⌘Command+/. Toggle line comment.⌘Command+C. Copy current cell.⌘Command+X. Cut current cell.⌘Command+V. Paste cell.⇧Shift+M. Merge with cell below.A. Insert a cell above.B. Insert a cell below.D. Delete current cell.G. Go to first cell.L. Toggle line numbers.O. Toggle cell output.T. Toggle cell title.
Repos
Databricks Repos support all following operation
- Clone, push to, or pull from a remote Git repository.
- Create and manage branches for development work.
- Create notebooks, and edit notebooks and other files.
- Visually compare differences upon commits.
However, the following tasks are not supported by Databricks Repos, and must be performed in your Git provider:
- Create a pull request.
- Resolve merge conflicts.
- Merge or delete branches.
- Rebase a branch.
Repos vs Notebooks
One advantage of Databricks Repos over the built-in Notebooks versioning is that Databricks Repos supports creating and managing branches for development work.
SQL
Databricks SQL is a data warehouse on the Databricks Lakehouse Platform that lets you run all your SQL and BI applications at scale.
02 - Delta Lake
2.1 What is Delta Lake?
Delta Lake is an open-source project that enables building a data lakehouse on top of existing storage systems.
Delta Lake is Not…
- Proprietary technology
- Storage format
- Storage medium
- Database service or data warehouse
Delta Lake is…
- Open Source project.
- Builds on standard data formats
- Apache Parquet
- JSON
- Optimised for cloud object storage
- Object storage is cheap, durable, highly available, and affectively infinitely scalable.
- Built for scalable metadata handling
- Delta Lake is designed to resolve the problem of quickly returning point queries .
In summary, Delta Lake
- decouple compute and storage cost
- provide optimised performance for data
- regardless of data scale
Because Delta Lake is open source, leveraging open format, storing data in the customised cloud object storage, and designed for infinity scalability.
Choosing to migrate your data to Delta Lake represent an investment in the long-term performance and liability.
The Data Lakehouse is built on top of this foundation, with the vision of powering applications and queries through your organisation from a single copy of the data.
2.2 ACID Guarantee
Delta Lake brings ACID to object storage
- Atomicity means that all transactions either succeed or fail completely.
- Consistency guarantees relate to how a given state of the data is observed by simultaneous operations.
- Isolation refers to how simultaneous operations potentially conflict with one another.
- Durability means committed changes are permanent.
Problems solved by ACID
- Hard to append data.
- Modification of existing data difficult.
- Jobs failing mid way.
- Real-time operations hard.
- Costly to keep historical data versions.
2.3 Managing Delta Lake Table
Creating Delta Lake Table
We can create a Delta Lake table students with following SQL query:
| |
Note: In Databricks Runtime 8.0 and above, Delta Lake is the default format and you don’t need USING DELTA.
Now, let’s insert some data to the table
| |
Note: Databricks doesn’t have a COMMIT keyword, transaction run as soon as they’re executed, and commit as they succeed.
Query data from Delta Lake Tables
| |
Delta Lake guarantees that any read against a table will always return the most recent version of the table, and that you’ll never encounter a state of deadlock due to ongoing operations.
Table reads can never conflict with other operations, and the newest version of your data is immediately to all clients that can query your lakehouse. Because all transaction information is stored in cloud object storage alongside your data files, concurrent reads on Delta Lake tables is only limited by the hard limits of object storage on cloud vendors.
Note: It’s not infinite, but it’s at least thousands of reads per second.
- AWS
- Azure
- GCP
Note: There are other Delta Lake limitations on AWS S3 when using multi-cluster write to same Delta Lake table, see details
Insert, update, and delete records in Delta Lake Tables
We can use the update clause to update record values in Delta Lake tables
| |
We can use delete clause to delete certain records in a table
| |
Write upsert statements with Delta Lake
| |
We can use merge clause to achieve upsert function with a Delta Lake table
| |
Note: Merge statement must have at least one field to match on, and each WHEN MATCHED or WHEN NOT MATCHED clause can have any number of additional conditional statements
Drop Delta Lake Tables
We can use drop clause to drop a Delta Lake table
| |
There are two types of tables in Delta Lake
- Managed Table.
- Managed Table are tables whose metadata and the data are managed by Databricks.
- When you run the
DROP TABLEon a managed table, both the metadata and the underlying data files are deleted.
- External Table.
- External Tables are tables whose metadata are managed by Databricks.
- When you run the
DROP TABLEcommand, only the metadata will be deleted.
2.4 Advanced Delta Lake Features
Examine Table Details
By default, Databricks uses a Hive metastore to register databases, tables, and views.
We can use DESCRIBE EXTENDED to see important metadata about our table.
| |
We can also use DESCRIBE DETAIL to display more table metadata.
| |
The default location of Hive metastore is
| |
Describe the directory structure of Delta Lake files
A Delta Lake table is actually backed by a collection of files stored in cloud objects. We could use the following command to have a close look at these files.
| |
It will yield something like
| |
Note that you can see a folder _delta_log and a bunch of Apache Parquet formatted files. The Parquet files are the actual data files. And the _delta_log folder is the primary directory to store all Delta Lake table transaction records.
We can peek inside the _delta_log to see more
| |
The results will be something like
| |
Use OPTIMIZE to compact small files
For Delta Lake tables, we can use the command OPTIMIZE to combine files toward an optimal size (scaled based on the size of the table).
When executing OPTIMIZE command, suers can optionally specify one or several fields for ZORDER indexing. While the specific match for Z-order is unimportant, it speeds up data retrieval when filtering on provided fields by colocating data with similar values within data files.
| |
Result
| |
Reference: Delta Optimise
Use ZORDER to index tables
Review a history of table transactions
We can use DESCRIBE HISTORY command to return provenance information, including operation, user and so on for each write to a table.
Table history is retained for 30 days.
| |
Results
| |
Reference: Delta history
Query previous table version
With all the table history information, we can easily query previous table version
| |
Time travel in Delta Lake tables are not recreating a previous state of the table by undoing transactions against our current version, rather, we’re just querying all these data files that were indicated as valid as of the specified version.
Roll back to previous table version
To roll back to previous table version, we just need to use the RESTORE command
| |
Note that a RESTORE command is recorded as a transaction as well, you won’t be able to completely hide the fact you accidentally deleted all the records in the table (xp), but you will be able to undo the operation and bring your table back to a desired state.
| |
Reference: Delta RESTORE
Clean up stale data files with VACUUM
Databricks will automatically clean up stale files. If you wish to manually purge old data files, this can be performed with the VACUUM operation.
By default, VACUUM will prevent you from deleting files less than 7 days old, just to ensure that no long-running operations are still referencing any of the files to be deleted. But you can configure Delta Lake with following knobs to enable deleting files less than 7 days.
| |
If you run VACUUM on a Delta table, you lose the ability time travel back to a version older than the specified dat retention period.
Reference: Delta Vacuum
03 - Relational Entities On Databricks
3.1 Databases and Tables on Databricks
Check table details
We can use the DESCRIBE DETAIL command to get detailed table information.
| |
Load a CSV file into external table:
- create a temporary view to load csv file
- create an external table with specified external location, and then insert data from temporary view into this external table.
| |
Views, Temporary View & Global Temporary View
Normal View
We can use the CREATE VIEW statement to create normal view as we know.
| |
Temporary View
We can add the TEMPORARY keyword to create a temporary view
| |
Global Temporary View
There is also another concept, GLOBAL TEMPORARY VIEW in Databricks
| |
Temporary view vs Global Temporary view
TEMPORARY VIEW are session-scoped and will be dropped when session ends because it skips persisting the definition in underlying metastore. GLOBAL TEMPORARY views are tied to a system preserved temporary database global_temp.
04 - ETL with Spark SQL
Query Single File
In Databricks, we can use SQL to directly query a single file
| |
Results
| |
Query a Directory of Files
Apart from querying a file, we can also use Databricks to query a directory like
| |
Results
| |
Extract Text Files as Raw Strings
When working with text-based files (e.g. JSON, CSV, TSV, TXT formats), you can use the text format to load each line of the file as row with one string column named value.
| |
Results
| |
This can be useful when data sources are prone to corruption and customer text parsing functions will be used to extract values from text fields.
Create a table based on External CSV files
In Databricks, we can create a table based on a csv file or a directory of csv files. What we need to do is to specify
- column names and types
- file format
- delimiter used to separate fields
- presence of a header
- path to where this data is located
Example Spark DDL query:
| |
Note
- For the sake of performance, Spark will automatically cached previously queried data in local storage.
- External data source is not configured to tell Spark that the underlying data files need to refresh.
- But we can manually refresh the cache of our data by running the
REFRESH TABLEcommand.
| |
Extracting Data from SQL Databases via JDBC Connection
Databricks does provide a standard JDBC driver so that we can use Spark SQL to connect with an external database, like following:
| |
Note
- Even through Databricks can talk to various database & data warehouses, it’s recommended to either
- Moving the entire source table(s) to Databricks and only transferring the results back to Databricks
- Pushing down the query to the external SQL databases and only transferring the results back to Databricks
- In either case, working with very large datasets in external SQL databases can incur significant overhead because of
- Network transfer legacy associated with moving all data over the public internet
- Execution of query logic in source systems not optimised for big data queries
Create Table as Select (CTAS)
CREATE TABLE AS SELECT statements create and populate Delta tables using data retrieved from an input query.
| |
CTAS statements will automatically infer schema information from query results, and do not support manual declaration.
- useful for external data ingestion from sources with well-defined schema, like Apache Parquet and tables.
- don’t support specifying additional file options.
To create a table with comments, you can do something like
| |
Note: Remember the comments will straight follow the create statement
CTAS for External Data Source
| |
CTAS for Renaming Columns from Existing Tables
We could use CTAS to rename a column from an existing tables.
| |
Table Constraint
Because Delta Lake enforces schema on write, Databricks can support standard SQL constraint management clauses to ensure the quality and integrity of data added to a table.
Currently Databricks support two types of constraints :
- NOT NULL constraints . indicates that values in specific columns cannot be null.
- CHECK constraints . indicates that a specified boolean expression must be true for each input row.
NOT NULL Constraint
| |
CHECK Constraint
| |
Primary Key & Foreign Key Constraints
Databricks is also going to release the Primary Key and Foreign Key relationships on fields in Unity Catalog tables in the short future.
You can declare primary keys and foreign keys as part of the table specification clause during table creation. This clause is not allowed during CTAS statements. You can also add constraints to existing tables.
| |
Cloning Delta Lake Tables
Delta Lake has two options for efficiently coping Delta Lake tables.
DEEP CLONE.- fully copies data and metadata from a source table to a target.
- This copy occurs incrementally, so executing this command again can sync changes from the source to the target location.
SHALLOW CLONE.- create a copy of a table quickly to test out applying changes without the risk of modifying the current table.
- Just copy the Delta transaction logs, aka table metadata, meaning that data doesn’t move.
- This is similar to Snowflake’s Zero Copying Cloning
- In either case, data modifications applied to the cloned version of the table will be tracked and stored separately from the source. Cloning is a great way to setup tables for testing SQL code while still in development
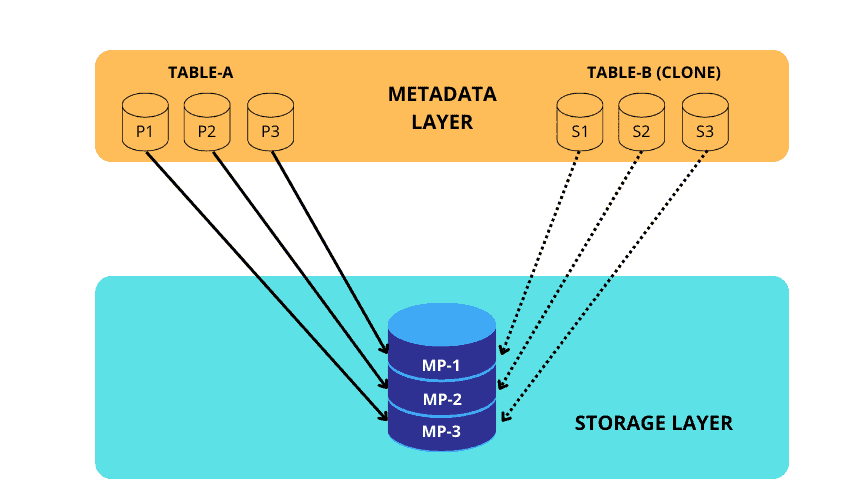
DEEP CLONE
| |
SHALLOW CLONE
| |
Writing to Delta Tables
Complete Overwrite
We can use overwrites to atomically replace all of the data in a table. There are multiple benefits to overwriting tables instead of deleting and recreating tables:
- overwriting a table is much faster because it doesn’t need to list the directory recursively or delete any files.
- the old version of the table still exists; can easily retrieve the old data using Time Travel.
- it’s an atomic operation. Concurrent queries can still read the table while you are deleting the table.
- Due to ACID transaction guarantees, if overwriting the table fails, the table will be in its previous state.
In Databricks, we could use CREATE OR REPLACE TABLE (CRAS) statements fully replace the contents of a table each time they execute.
| |
And we can use DESCRIBE HISTORY command to retrieve the table history.
| |
Result
| |
INSERT OVERWRITE
INSERT OVERWRITE provides a nearly identical outcome like CRAS, data in the target table will be replaced by data from the query.
- Can only overwrite an existing table, not create a new one like our CRAS statement.
- Can overwrite only with new records that match the current table schema, and thus can be a safer technique for overwriting an existing table without disrupting downstream consumers.
- Can overwrite individual partitions.
| |
INSERT INTO
We can use INSERT INTO to atomically append new rows to an existing Delta table. This allows for incremental updates to existing table, which is much more efficient than overwriting each time.
| |
Note INSERT INTO does not hae any built-in guarantees to prevent inserting the same records multiple times. Re-executing the above cell would write the same records to the target table, resulting in duplicate records.
MERGE INTO
You can upsert data from a source table, view or DataFrame into a target Delta table using the MERGE INTO command. Delta Lake supports inserts, updates and deletes in MERGE INTO, and supports extended syntax beyond SQL standards for advanced use cases.
| |
The main benefits with MERGE INTO are
- updates, inserts and deletes are completed as a single transaction.
- multiple conditionals can be added in addition to matching fields.
- provides extensive options for implementing custom logic.
Insert-Only Merge for Deduplication
A common ETL use case is to collect logs or other every-appending datasets into a Delta table through a series of append operations.
Many source systems can generate duplicate records. With Merge, you can avoid inserting the duplicate records by performing an insert-only merge.
This optimised command uses the same MERGE INTO syntax but only provide a WHEN NOT MATCHED clause.
Below we use this to confirm that records with the same user_id and event_timestamp aren’t already in the events table.
| |
COPY INTO
COPY INTO provides SQL engineers an idempotent option to incrementally ingest data from external systems.
Note that this operation does have some expectations:
- Data schema should be consistent.
- Duplicate records should try to be excluded or handled downstream.
This operation is potentially much cheaper than full table scans for data that grows predictably.
| |
Advanced SQL Transformation
Interacting with JSON Data
We could use : to query nested JSON data, parse and extract the information that we need
| |
Spark SQL provides following functions
from_json. Thefrom_jsonfunction requires a schema.schema_of_json.
| |
Results
| |
Once a JSON string is unpacked to a struct type, Spark supports *(star) unpacking to flatten fields into columns.
| |
Results
| |
Interaction with Arrays
size()function provides a count of the number of elements in an array for each row.explode()function lets us put each element in an array on its own row, i.e. flatten the array.collect_set()function can collect unique values for a field, including fields within arrays.flatten()function allows multiple arrays to be combined into a single array.array_distinct()function removes duplicate elements from an array.
| |
Set Operators
UNIONreturns the collection of two queries.MINUSreturn all rows found in one dataset but not the other.INTERSECTreturn all rows found in both relations.
Pivot Tables
PIVOT clause is used for data perspective. We can get the aggregated values based on specific column values, which will be returned to multiple columns used in the SELECT clause. The PIVOT clause can be specified after the table name or subquery.
Pivot transforms the rows of a table by rotating unique values of a specific column list into separated columns. In other word, it converts a table from a long format to a wide format.
Here we use PIVOT to create a new transactions table that flattens out the information contained in the sales table. This flattened data format can be useful for dashboarding, but also useful for applying machine learning algorithms for inference or prediction.
| |
High-order Functions
FILTER()filters an array using the given lambda function.EXISTS()tests whether a statement is true for one or more elements in an array.TRANSFORM()uses the given lambda function to transform all elements in an array.REDUCE()takes two lambda functions to reduce the elements of an array to a single array value by merging the elements into a buffer, and then apply a finishing function on the final buffer.
filter()
| |
transform()
| |
SQL UDFs
At minimum, a SQL UDF requires a function name, optional parameters, the type to be returned, and some custom logic.
| |
The above code defines a function named yelling() that takes one parameter text, and returns a string that will be uppercase letters with three exclamation points to the end.
We can directly use the yelling() in our select statement.
| |
We could use DESCRIBE FUNCTION or DESCRIBE FUNCTION EXTENDED command to get all function details
| |
Results
| |
exists()
aggregate()
05 - Python for Spark SQL
06 - Incremental Data Processing
Auto Loader
Databricks Auto Loader provides an easy-to-use mechanism for incrementally and efficiently processing new data files as they arrive in cloud file storage.
Auto Loader keeps track of discovered files using Checkpointing in the checkpoint location. Checkpoints allows Auto Loader to provide exactly-once ingestion guarantees.
The following is an example function that to demonstrate using Databricks Auto Loader with PySpark API, includes both a Structured Streaming read and write.
| |
The Auto Loader query we configured will automatically detects and processes records from the source directory into the target table. There is a slight delay as records are ingested, but an Auto Loader query executing with default streaming configuration should update results in near real time.
Auto Loader vs Delta Live Table
Auto Loader allows incrementally data ingestion into Delta Lake from a variety of data sources.
While Delta Live Table is used for defining end-to-end data pipelines by specifying the data source, the transformation logic, and destination state of the data, instead of manually stitching together siloed data processing jobs.
In effect Auto Loader would be a piece of the DLT pipeline specifically on the data source side as raw data is incrementally brought into Delta Lake. DLT would then pick up from there for the downstream transformation and processing of the data as illustrated.
Spark Structured Streaming
The magic behind Spark Structured Streaming is that it allows users to interact with ever-growing data sources as if they were just a static table of records.
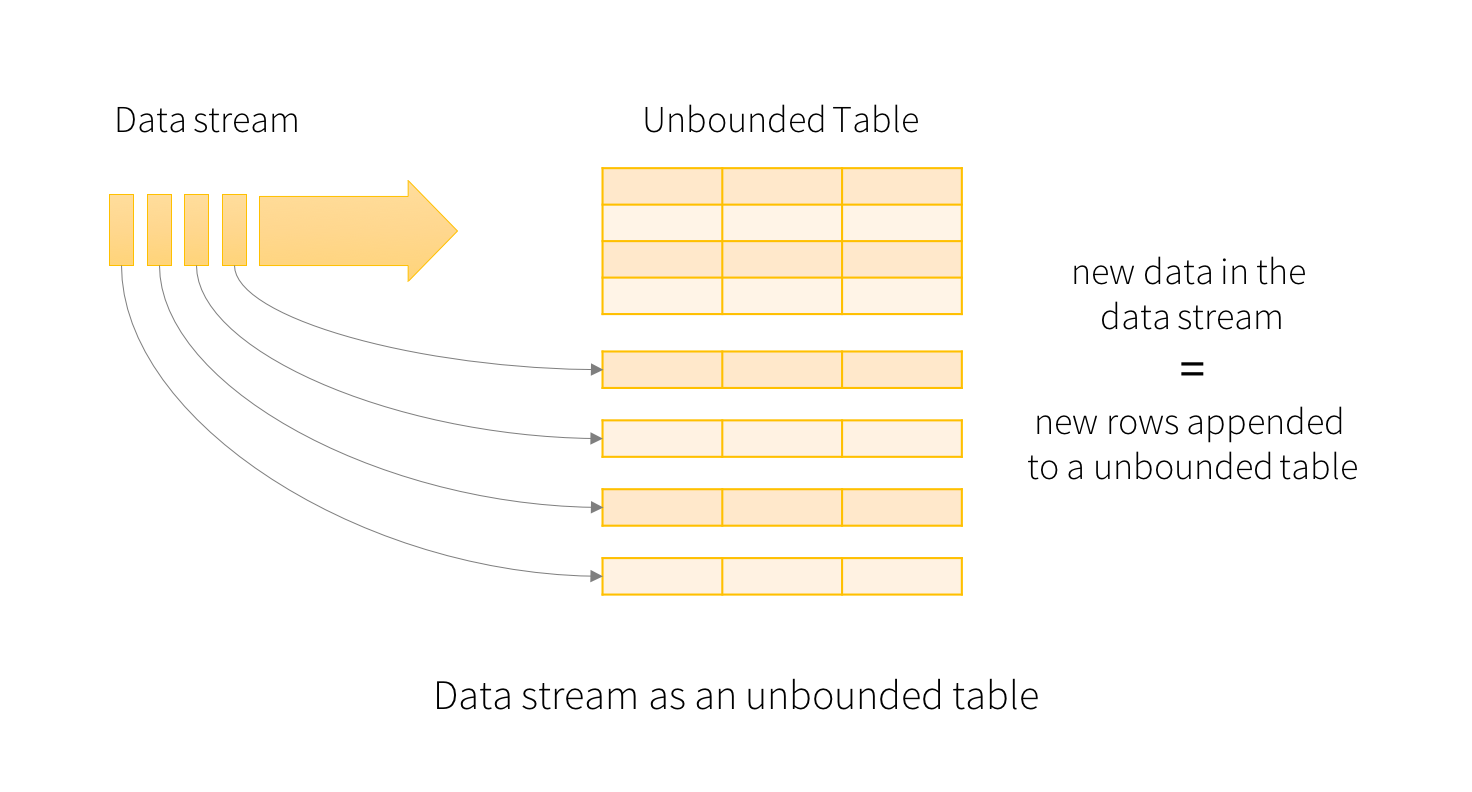
A data stream describes any data source that grows over time. Structured Streaming lets us define a query against the data source and automatically detect new records, and propagate them through previously defined logic.
Read a Stream
The spark.readStream() method returns a DataStreamReader used to configure and query the stream.
| |
When we execute a query on a streaming temporary view, we’ll continue to update the results of the query as new data arrives in the source. Think of a query executed against a streaming temp view as an always-on incremental query.
Write a Stream
To persist the results of a streaming query, we must write them out to durable storage. The DataFrame.writeStream method return a DataStreamWriter used to configure the output.
When writing to Delta Lake tables, we typically will only need to worry about 3 settings:
- Checkpoint.
- Databricks creates checkpoints by storing the current state of your streaming job to cloud storage.
- Checkpointing combines with write ahead logs to allow a terminated stream to be restarted and continue from where it left off.
- Checkpoints cannot be shared between separate streams. A checkpoint is required for every streaming write to ensure processing guarantees.
- Output Modes. There are two outputs modes.
- Append.
.outputMode("append"). This is the default mode, and only newly appended rows are incrementally appended to the target table with each batch. - Complete.
.outputMode("complete"). The results table is recalculated each time a write is triggered, the target table is overwritten with each batch.
- Trigger Intervals. There are four trigger intervals.
- Unspecified. This is the default, and equivalent to
processingTime=500ms. - Fixed Interval micro-batches.
.trigger(processingTime="2 minutes"). The query will be executed in micro-batches and kicked off at the user-specified intervals. - Triggered micro-batch.
.trigger(once=True). The query will execute a single micro-batch to process all the available data and then stop on its own. - Triggered micro-batches.
.trigger(availableNow=True). The query will execute multiple micro-batches to process all the available data and then stop on its own.
07 - Multi-hop Architecture
Delta Lake allows users to easily combine streaming and batch workloads in a unified multi-hop pipeline. Each stage of the pipeline represents a state of our data valuable to driving core use cases within the business.
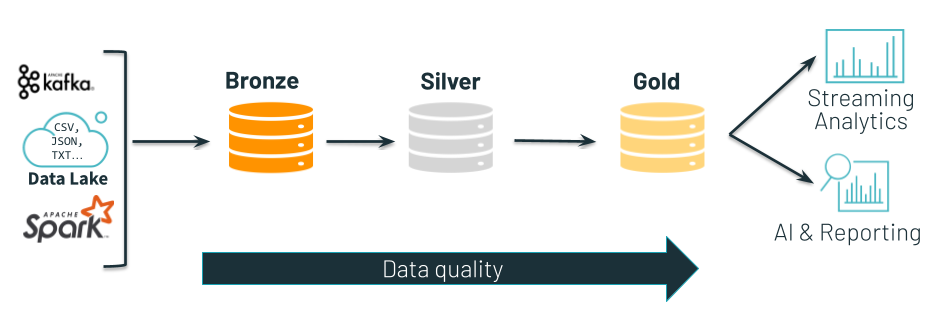
- Bronze tables contains raw data ingested from various sources (JSON files, RDBMS data, IoT data, to name a few examples).
- Silver tables provide a more refined view of our data. We can join fields from various bronze tables to enrich streaming records, or update account statuses based on recent activity.
- Gold tables provide business level aggregations often used for reporting and dashboarding. This would include aggregation such as daily active site users, weekly sales per store, or gross revenue per quarter by department.
08 - Delta Live Table
Delta Live Table Pipeline
There are two types DLT Pipelines:
- Continuous Pipeline
- Triggered Pipeline
Continuous Pipeline
Continuous Pipelines update tables continuously as input data changes. Once an update is started, it continues to run until the pipeline is shutdown.
In Development mode, the Delta Live Table system ease the development process by
- Reusing a cluster to avoid the overhead of restarts. The cluster runs for two hours when development mode is enabled.
- Disabling pipeline retries so that you can immediately detect and fix errors.
Triggered Pipeline
Triggered Pipelines update each table with whatever data is currently available and then they shutdown.
In Production Mode, the Delta Live Table system:
- Terminates the cluster immediately when the pipeline is stopped.
- Restarts the cluster for recoverable errors, e.g. memory leak or stale credentials.
- Retries execution in case of specific errors, e.g. a failure to start a cluster.
Managing Data Quality with Delta Live Tables
You use expectations to define data quality constraints on the contents of a dataset. Expectations allow you to guarantee data arriving in tables meets data quality requirements and provide insights into data quality for each pipeline update. You apply expectations to queries using Python decorators or SQL constraint clauses.
Retain invalid records
| |
Drop invalid records
| |
Fail on invalid records
| |
With ON VIOLATION FAIL UPDATE, records that violate the expectation will cause the pipeline to fail. Whe a pipeline fails because of an expectation violation, you must fix the pipeline code to handle the invalid data correctly before re-running the pipeline.
SQL For Delta Live Table
At its simplest, you can think of DLT SQL as a slight modification to traditional CTAS statements. DLT tables and views will always be preceded by the LIVE keywords.
Auto Loader syntax for DLT
Delta Live Tables provides slightly modified Python syntax for Auto Loader, and adds SQL support for Auto Loader.
| |
Note
- Delta Live Tables will automatically configures and manages the schema and checkpoint directories when using Auto Loader to read files.
- If you manually configure either of these directories, performing a full refresh does not affect the contents of the configured directories.
- Databricks recommends using the automatically configured directories to avid unexpected side efforts during processing.
Delta Live Table Demo
09 - Task Orchestration with Jobs
Notification
Job Alerts
To notify when runs of this job begin, complete, or fail, you can add one or more email addresses, or system destinations (e.g. webhook destination or Slack).
Notifications you set at the job level are not sent when failed tasks are retried. To receive a failure notification after every failed tasks, including every failed retry, we need to use Task Notification instead.
Destination Type
- Slack
- Webhook
- Microsoft Teams
- PagerDuty
- Amazon Simple Email Service (SES) and Simple Notification Service (SNS)
10 - Running a DBSQL Query
11 - Managing Permissions
Data Explorer
The Data Explorer allows users and admin to
- Navigate databases, tables and views.
- Explorer data schema, metadata, and history.
- Set and modify permissions of relational entities.
Configuring Permissions
By default, admins will have the ability to view all objects registered to the metastore and will be able to control permissions for other users in the workspace. Users will default to having no permissions on anything registered to the metastore, other than objects that they can create in DBSQL.
Generally, permissions will be set using Groups that have been configured by administrator, often by importing organisational structures from SCIM integration with a different identity provider.
Table Access Control Lists (ACLs)
Databricks allows you to configure permissions for the following objects:
- CATALOG. controls access to the entire data catalog.
- DATABASE. controls access to a database.
- TABLE. controls access to managed or external tables.
- VIEW. controls access to SQL views.
- FUNCTION. controls access to a named function.
- ANY FILE. controls access to the underlying filesystem. Users granted access to ANY FILE can bypass the restrictions put on the catalog, databases, tables, and views by reading from the filesystem directly.
Privileges
- ALL PRIVILEGES. gives all privileges (is translated into all the below privileges).
- SELECT. gives read access to an object.
- MODIFY. gives ability to add, delete, and modify data to or from an object.
- READ_METADATA. gives ability to view an object and its metadata.
- USAGE. does not give any abilities, but is an additional requirement to perform any action on a database object.
- CREATE. gives ability to create an object, e.g. a table in a database.
- CREATE_NAMED_FUNCTION. gives ability to create a named UDF in an existing catalog or schema.
Admin Configuration
To grant permission to certain team, we could do
| |
To confirm results, we can run
| |