
What is a Data Lakehouse?
History of Data Warehouse
Pros
- Business Intelligence (BI)
- Analytics
- Structured & Clean Data
- Predefined Schemas
Cons
- Not support semi or unstructured data
- Inflexible schemas
- Struggled with volume and velocity upticks
- Long processing time
History of Data Lake
Pros
- Flexible data storage
- Structured, semi-structured, and unstructured data
- Steaming support
- Cost efficient in the cloud
- Support for AI and Machine Learning
Cons
- No transactional support
- Poor data reliability
- Data Lake are not supportive of transactional data, and cannot enforce data quality
- Primarily due to multiple data types
- Slow analysis performance
- Because large volume of data, the performance of analysis is slower
- the timeliness of decision-making results has never manifested
- Data governance concerns
- Governance over the data in a data lake creates challenges with security, and privacy enforcement due to the unstructured nature of the contents of a data lake
- Data Warehouse still needed
Problems with Complex Data Environment
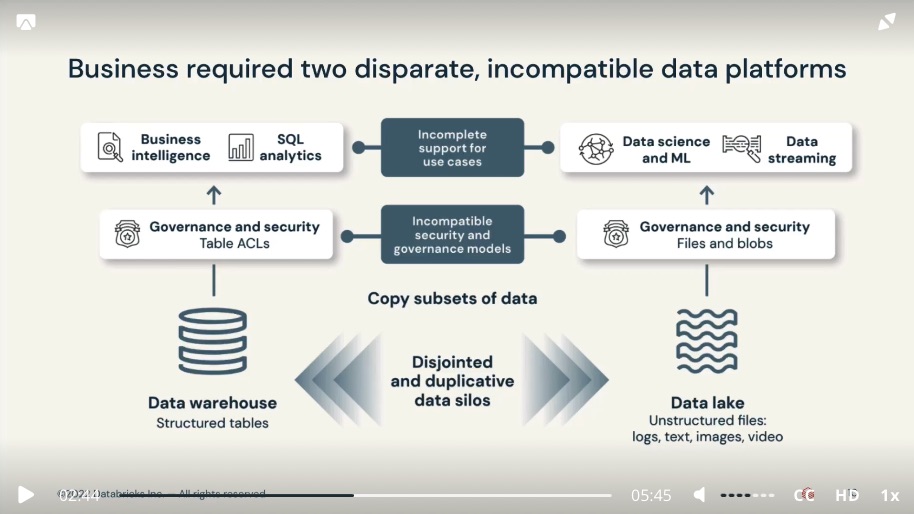
- Data Lake didn’t fully replaced Data Warehouse for reliable BI insights, Business has implemented complex systems to have Data Lake, Data Warehouse, and additional systems to handle streaming data, machine learning and artificial intelligence requirements.
- Such environment introduced complexity and delay as data teams were stuck in silos, completing disjointed work.
- Data had to be copied between the systems and in some cases copied back, impacting oversight and data usage governance
- not to mention the cost of storing the same information twice with disjointed systems
Data Lakehouse
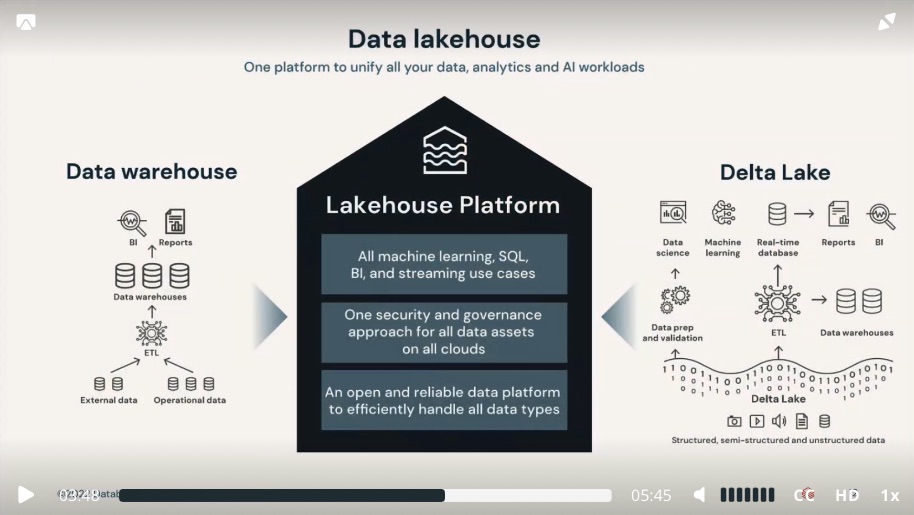
- a combined open architecture that combine data lake with the analytical power and controls of a data warehouse.
- built on a data lake, a data lakehouse can store all data of any type together
- becoming a single reliable source of truth, providing direct access for AI and BI together.
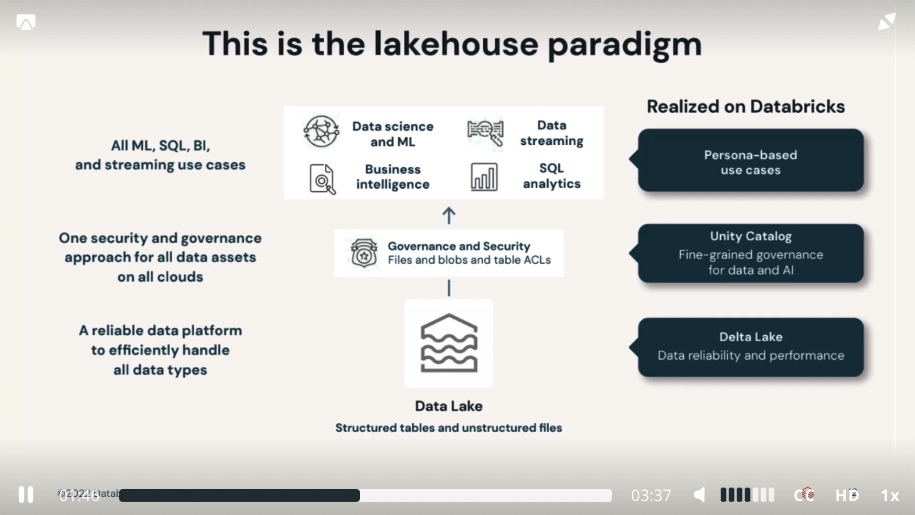
Key features
- Transaction support
- Schema enforcement and governance
- Data governance
- BI Support
- Decoupled storage form compute
- Open storage formats
- Support for diverse data types
- Support for diverse workloads
- data science
- machine learning
- sql analytics
- end-to-end streaming
The Data Lakehouse essentially is the modernised version of a data warehouse, providing all the benefits and features without compromising the flexibility in depth of a data lake.
Databricks Architecture Overview
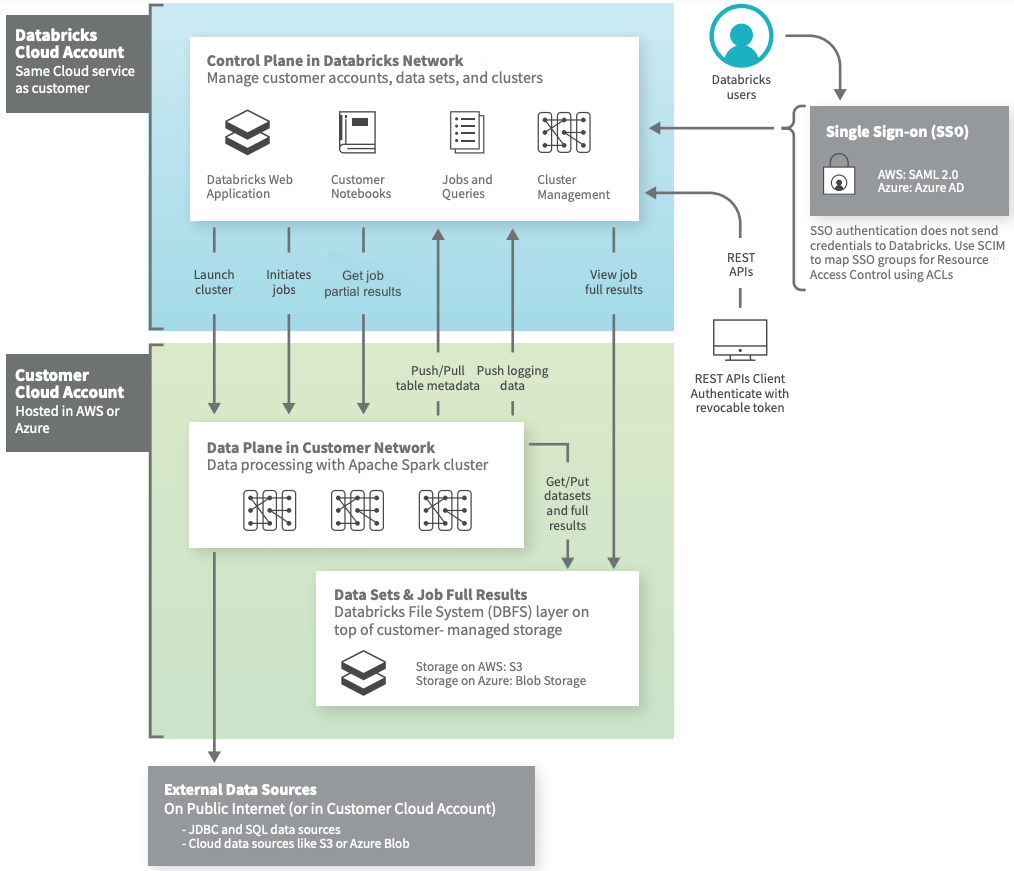
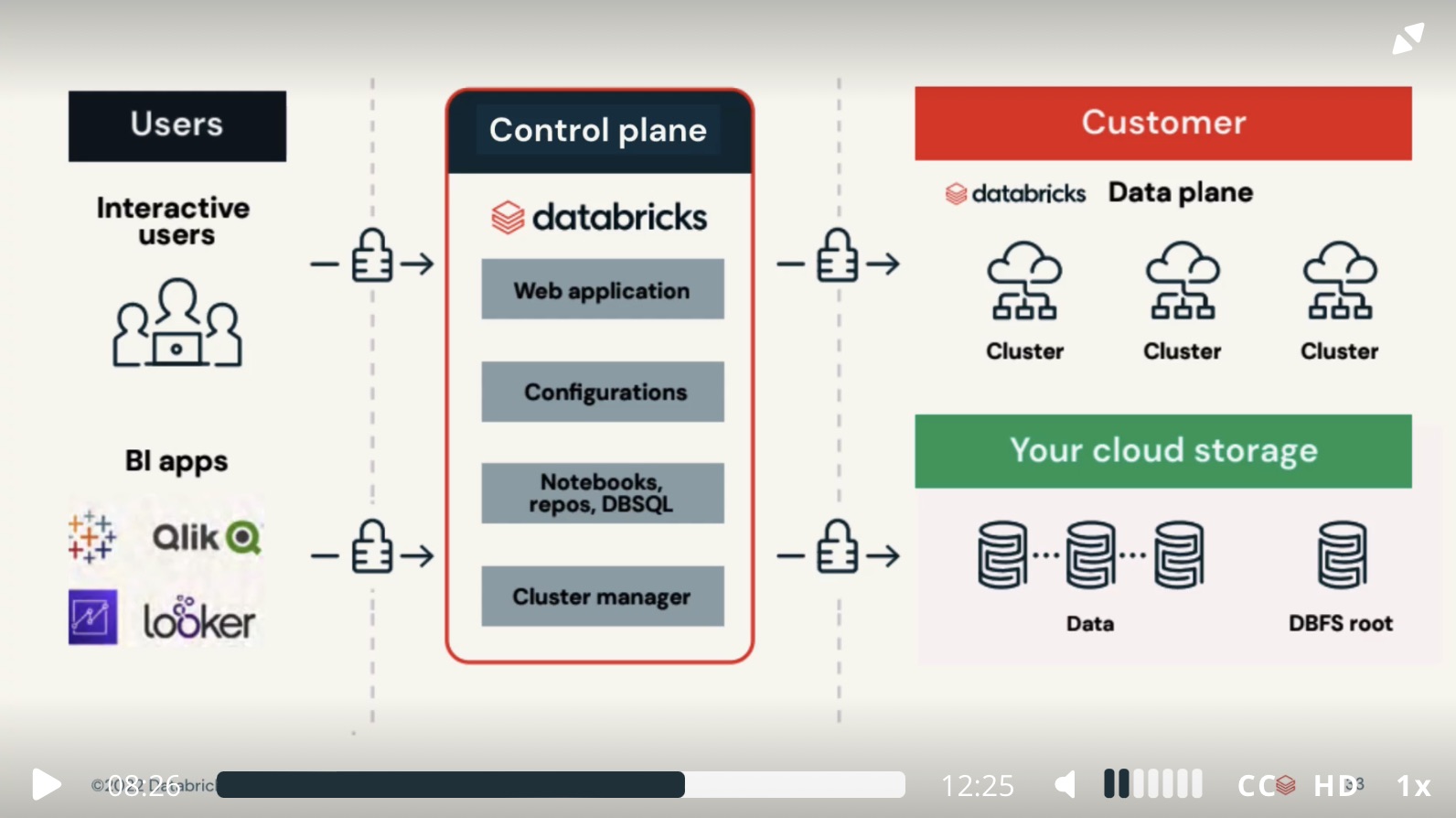
Databricks operates out of a control plane, and a data plane.
- The
Control Planeincludes the backend service that Databricks manages in its own AWS account. Notebook commands and many other workspace configurations are stored in the control plane and encrypted at rest. - The
Data Planeis where your data is processed- Fro most Databricks computation, the compute resources are in your AWS account in what is called the Classic data plane. This is the type of data plane Databricks uses for notebooks, jobs, and for pro and classic Databricks SQL warehouses.
- If you enable Serverless compute for Databricks SQL, the compute resources for Databricks SQL are in a shared Serverless data plane. The compute resources for notebooks, jobs and pro and classic Databricks SQL warehouses still live in the Classic data plane in the customer account.
Lakehouse Platform Architecture
Problem with Data Lake
- Lack of ACID transaction support
- Lack of schema enforcement
- Lake of integration with a data catalog
- Too many small files
Delta Lake
- ACID transaction guarantees
- Scalable data and metadata handling
- Audit history and time travel
- Schema enforcement and schema evolution
- Support for deletes, updates, and merges
- Unified streaming and batch data processing
- Additional
- compatible with Apache Spark
- Uses Delta Tables
- Has a transaction log
- Open-source project
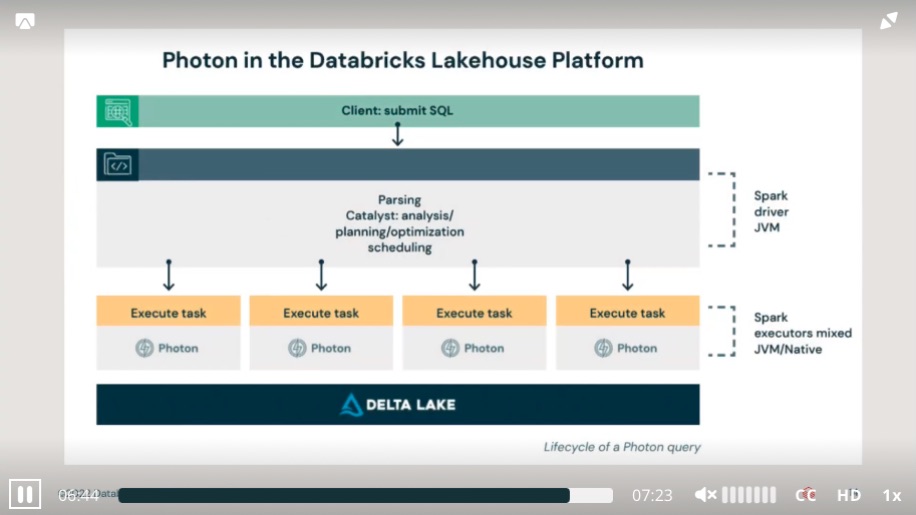
Photon
- Execution engine to support Lakehouse
Unified Governance and Security
Challenges to data and AI Governance
- Diversity of data and AI assets
- Using two disparate and incompatible data platforms
- Data Warehouse for BI, and Data Lake for AI
- Rise of multi-cloud adoption
- Fragmented tool usage for data governance
Databricks’ Solution to solve above challenges
- Unity Catalog is a unified governance solution for all data assets.
- Delta Sharing, as an open solution to securely share live data to any computing platform
- Control Plane
- Data Plane
Unity Catalog
- Unity Catalog is a unified governance solution for all data assets.
- Modern lakehouse system support fine-grained row, column, and view level access control
- SQL
- query auditing
- attribute-based access control
- data visioning
- data quality
- Unity Catalog allows you to restrict access to certain rows and columns to users or groups authorized to query them, with attribute based access control
Delta Sharing
- Existing Data Sharing technology have several limitations
- traditional data sharing technologies do not scale well, often serve files offloaded to a server
- cloud object stores operate on an object level and are cloud specific
- commercial data sharing offerings often share tables instead of files

- Open cross-platform sharing
- Allow you to share existing data in Delta Lake and Apache Parquet Format
- Native integration with PowerBI, Tableau, Spark, Pandas, and Java
- Share live data without copying it
- Centralised administration and governance
- audit on table, partition, version level
- Marketplace for data products
- Privacy-safe data clean rooms
Control Plane
- Web Application
- Configurations
- Notebooks, Repos, DBSQL
- Cluster Manager
Data Plane
- Data Plane is where your data is processed
- unless you choose to use Serverless Compute, the compute resources in the data plane run inside the business owner’s own cloud account.
- All the data stay where it is.
Security in Data Plane
- Databricks clusters are typically short-lived, often terminated after a job, and do not persist data after termination.
- Code is launched in an unprivileged container to maintain system stability.
User Identity and Access
- Table ACLs feature
- IAM instance profiles
- Securely stored access key
- The Secrets API
Serverless Compute
Compute Resource Challenges
- Cluster creation is complicated
- Environment startup is slow
- Business cloud account limitations and resource options
- Long running clusters
- Over provisioning of resources
- Higher resource costs
- High admin overhead
- Unproductive users
Serverless Data Plane
- Three layers of isolation
- The container hosting the runtime
- The virtual machine hosting the container
- The virtual network for the workspace
Lakehouse Data Management Terminology
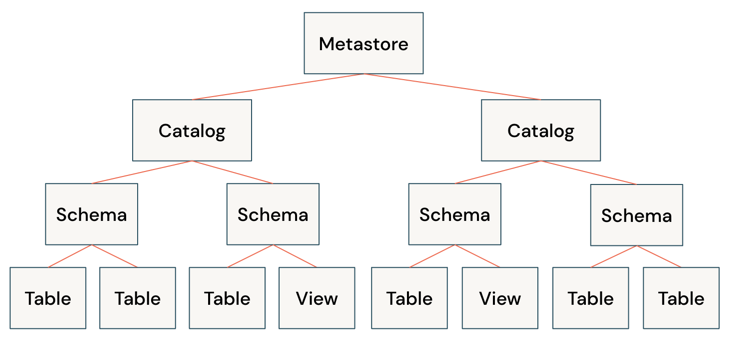
- Delta Lake
- Catalog . A grouping of databases.
- Database or schema. A grouping of objects in a catalog. Databases contain tables, views, and functions.
- Table
. A collection of rows and columns stored as data files in object storage.
- Managed table
- External table
- View . a saved query typically against one or more tables or data sources.
- Function . saved logic that returns a scalar value or set of rows.
Unity Catalog
- Centralised governance for data and AI
- Built-in data search and discovery
- Performance and scale
- Automated lineage for all workloads
- Integrated with your existing tools
- Unity Catalog namespacing model:
catalog_name.database_name.table_name
Supported Workloads: Data Warehousing
- Best price / performance
- Built-in governance
- A rich ecosystem
- Break down silos
Supported Workloads: Data Engineering
- Data is valuable business assets
Challenges to Data Engineering Support
Complex data ingestion methods
Support for data engineering principles
- CI/CD Pipeline
- Separation between Production and Development environments
- Testing before deployment
- Use Parameterisation to deploy and manage environments
- Uint Testing
- Documentation
Third-party orchestration tools
Pipeline and architecture performance tuning
Inconsistencies between data warehouse and data lake providers
A unified data platform with managed data ingestion, schema detection, enforcement, and evolution, paired with declarative, auto-scaling data flow integrated with a lakehouse native orchestrator that support all kinds of workflows.
Lakehouse Capacity
- Easy data ingestion
- Auto Loader
- COPY INTO
- Automated ETL pipelines
- Data quality checks
- Batch and streaming tuning
- Automatic recovery
- Data pipeline observability
- Simplified operations
- Scheduling and orchestration
Delta Live Tables
| |
Supported Workloads to Data Streaming
- Real-time Analysis. Analyse streaming data for instant insights and faster decisions.
- Real-time Machine Learning. Train models on the freshest data. Score in real-time.
- Real-time Applications. Embed automatic and real-time actions into business applications.
Reasons to use Databricks
- Build streaming pipelines and applications faster
- Simplify operations with automation
- Unified governance for real-time and historical data
Supported Workloads: Data Science & Machine Learning
Challenges to Data Science & Machine Learning Supported
- Siloed and disparate data systems
- Complex experimentation environments
- Getting models to production
- Multiple tools available
- Experiments are hard to track
- Reproducing results is difficult
- ML is hard to deploy
Capability
- Databricks Machine Learning Runtime
- MLflow
Reference
- Databricks Lakehouse Fundamentals