Basic Concepts
Dimensional Modelling
Dimensional modeling is widely accepted as the preferred technique for presenting analytic data because it addresses two simultaneous requirements:
- Deliver that that’s understandable to the business users
- Deliver fast query performance
Dimensional modelling always uses the concepts of facts and dimensions.
Facts, or measures are typically (but not always) numeric values that can be aggregated; Dimensions are groups of hierarchies and descriptors that define the facts.
For example, in a sale transaction dataset, sales amount is a fact; timestamp, product, region number, store number, etc. are elements of dimensions.
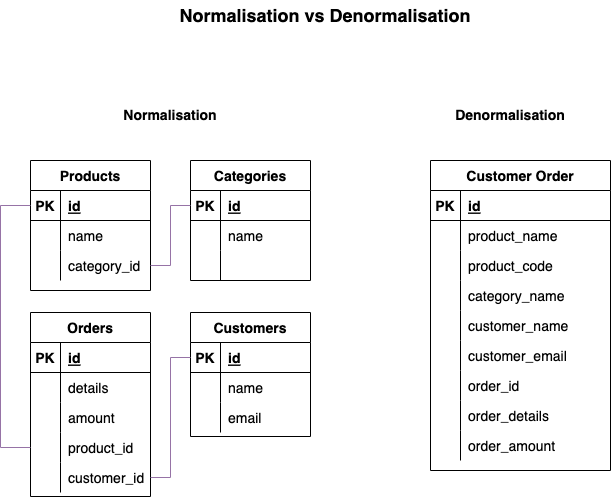
Normalisation vs Denormalisation
Normalised Data
A schema design to store non-redundant and consistent data.
- Data Integrity is maintained.
- Little to no redundant data.
- Many tables.
Denormalised Data
A schema that combines data so that accessing data (querying) is fast.
- Data Integrity is not maintained.
- Redundant data is common.
- Fewer tables.
Typical Data Warehouse Architecture
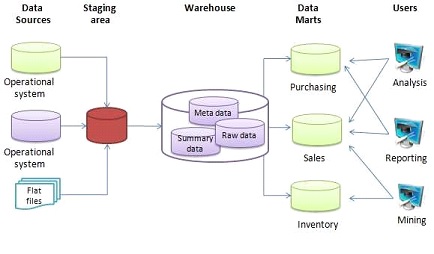
Staging / Integration Layer
- Create data in particular day
- Ensure all data comes from the same format
Data Warehouse / Data Vault
- All Data are having the same format
- Everything in 2NF
Data Marts
- Different department or team can have their dedicated Data Mart, with their own business logic applied.
- Provide information more quickly
- One user does data manipulation in his Data Mart will not affect other user in their Data Mart
ETL and Data Marts
- Extraction, Transformation and Loading
- Extraction. Get the Data
- Transformation. make it useful.
- Loading. Save it to the warehouse.
- Data Marts (Sub-sets of the Data Warehouse)
- Don’t mess with my data.
- Keep it simple for the user.
- Small problems are easier to solve
Schema Design
The dimensional model is built on a star-like schema or snowflake schema, with dimensions surrounding the fact table. To build the schema, the following design model is used:
- Choose the business process.
- Declare the grain
- Identify the dimensions
- Identify the fact
Step 1: Define business process
The basic in the design build on the actual business process which the data warehouse should cover. Therefore, the first step in the model is to describe the business process which the model builds on. To describe the business process, one you choose to do this in plain text or use basic Business Process Modeling Notation (BPMN) or other design guides like the Unified Modeling Language (UML).
Step 2: Declare the grain
The grain of the model is the exact description of what the dimensional model should be focusing on. This could for instance be “An individual line item on a customer slip from a retail store”. To clarify what the grain means, you should pick the central process and describe it w
Step 3: Identify the dimensions
Step 4: Identify the fact
Multidimensional Schemas
- Star Schema
- Snowflake Schema
- Kimball Model
Star Schema
Star Schema is the simplest type of Data Warehouse schema. In the Star Schema, the center of the star can have one fact tables and multiple associated dimension tables. It is also known as Star Join Schema and it optimised for querying large dataset.
Not in 3NF (Big Data)
- The data should be de-normalised to 2NF
- This means you get data redundancy
- This means you need more storage
- But you can get at the data more quickly
- The purposes of a DW is to provide aggregate data which is in suitable format for decision making.
Slowly Changing Dimensions (SCD)
Slowly Changing Dimensions (SCD) is a data management concept that determines how tables handle data which change over time.
For example, whether you want to overwrite values in the table or maybe retain their history. This can be determined by the SCD type to implement.
Deciding on which of a slowly changing dimension pattern to implement will vary based on your business requirements.
Type 0 SCD
In a Type 0 SCD table, no changes are allowed. Tables of this type are either static or append-only tables.
For example, static look-up tables.
Type 1 SCD
In a Type 1 SCD table, the new data overwrite the existing one. Thus, the existing data is lost as it is not stored anywhere else. This type is useful only when you care about the current values rather than historic comparisons.
Before adding new data:

In a Type 1 SCD table, no history will retain. When new data arrives, the old attributes values in the table’s rows are overwritten with the new values, like the following:
After adding new data:

Type 2 SCD
In a Type 2 SCD table, a new record is added with the changed data values. This new record become the current active record, while the old record is marked as no longer active. Type 2 SCD retains the full history of values.
For example, a products table that track prices changes overtime.
In Type 2 SCD table, table full changes history is retained. In order to support SCD Type 2 changes, we need to add three columns to our table
- Current. Which is a flag that indicates whether the record is the current version or not.
- Start Date. The date from which the record version is active.
- End date. The date to which the record version was active.
Before adding new data:

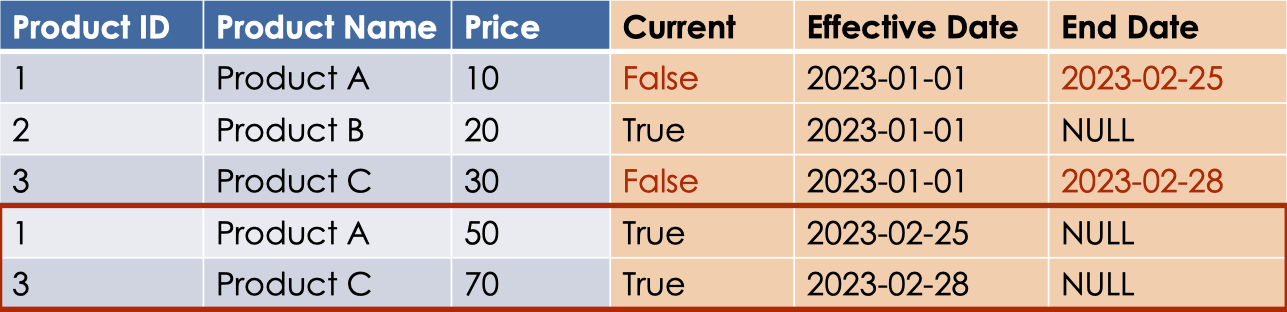 When new data arrives, a new record is added to the table with the updated attributes values,
When new data arrives, a new record is added to the table with the updated attributes values,
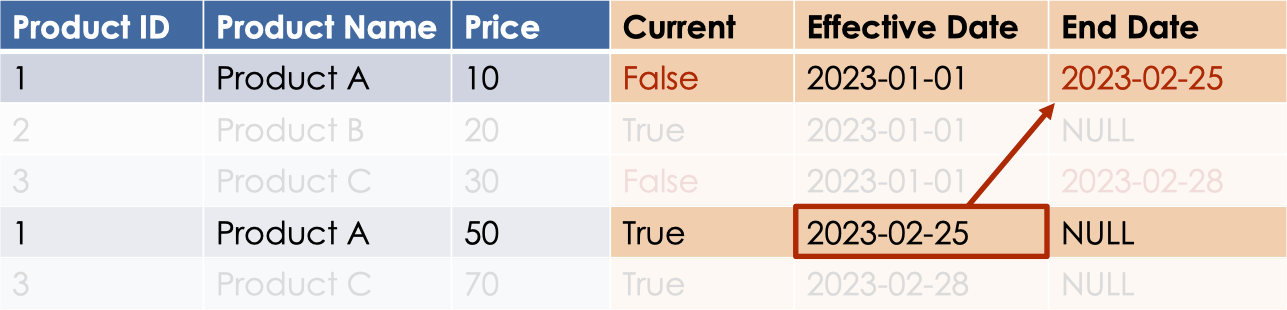
For example, the new record with the product_id no.1 become the current valid record, while the old record gets marked as no longer valid. And we set its End Date to the Start Date of the new record.
These effective/start and end dates help in calculating which record was valid during a particular time frame.
Change Data Capture (CDC)
Change Data Capture (CDC) is the process of identifying changes made to data in the source and delivering these changes to the target. These changes could be new records to be inserted from the source to the target, updated records in the source that need to be reflected in the target, and deleted records in the source that must be deleted in the target.
Changes are logged at the source as events that contains both the data of the records, along with the metadata information. These metadata indicate whether the specified record was inserted, updated, or deleted.