In this note, I am going to create my first Database and table in Snowflake, and load csv data files from AWS S3 into our table.
Typical Data Ingestion Process
- Prepare your files
- Stage the data
- Execute COPY command
- Managing regular loads
Loading data from AWS S3 Bucket
Step 1: Database and table initialization
So first of all, we need to create our database. Here we are creating a new database called OUR_FIRST_DATABASE and our table called OUR_FIRST_TABLE
| |
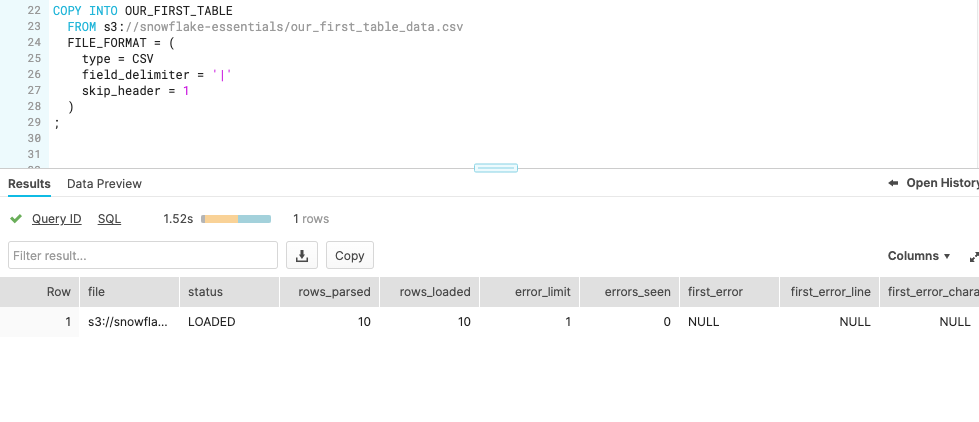
Step 2: Load data from AWS S3 bucket
Now we need to load the CSV file from AWS S3 into our table OUR_FIRST_TABLE, here we can use the command COPY INTO to achieve that:
| |
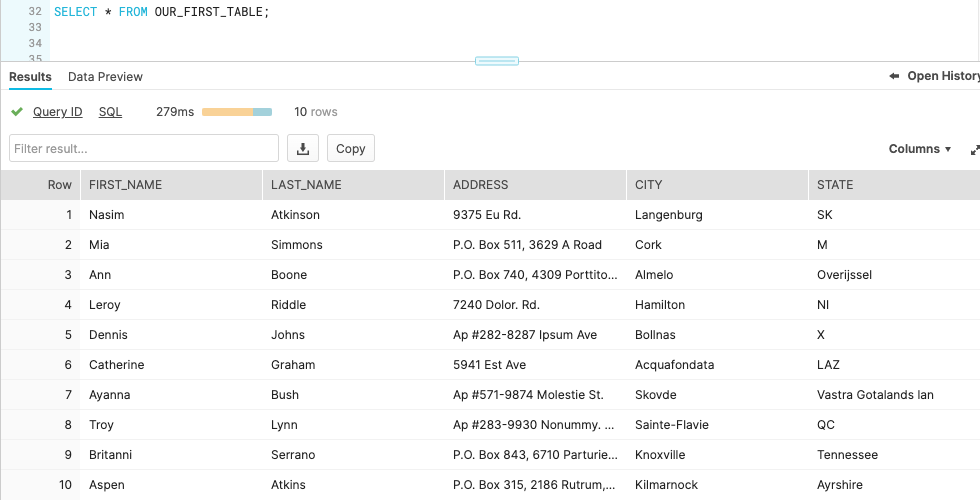
Step 3: Data Validation
After the data loading processing is completed, we need to validate our data is correct or not.
| |