Lambda Architecture
Lambda Architecture is a data processing model that can combine a traditional batch pipeline with a fast real-time stream pipeline for real-time data, as well as serving layer for responding to queries.
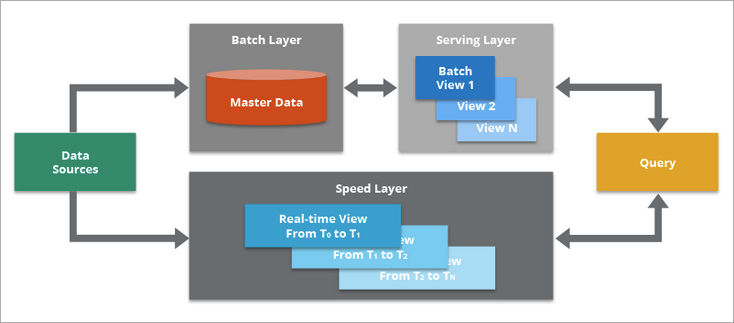
Main Components
The main components of Lambda Architecture are:
- Data Source. Your data environment might be complex and have multiple different data sources.Data can be ingested into your Data Lake directly, or obtained from various data sources with a Message Bus as intermediary store layer. Message Bus like Apache Kafka might not be the original data source, but can play as intermediary store layer for different data delivery velocity systems.
- Batch Layer. This component saves all data coming into the system as batch views in preparation for indexing. Normally the data is treated as immutable and append-only to ensure a trusted record of all incoming data.
- Serving Layer. This layer incrementally indexes the latest batch views to make it queryable by end users. This layer can also re-index all data to fix a coding bug or to create different indexes for different use cases.
- The key requirements in the serving layer is that the processing is done in an extremely parallelized way to minimize the time to index the dataset.
- While an indexing job is run, newly arriving data will be queued up for indexing in the next indexing job.
- Speed Layer. This layer complements the serving layer by indexing the most recently added data not yet fully indexed by serving layer. This includes the data that the serving layer is currently indexing as well as new data that arrived after the current indexing job started.
- Speed Layer typically leverages stream processing technologies to index the incoming data in near real-time to minimize the latency of getting the data available for querying.
- Query. This component is responsible for submitting end user queries to both the serving layer and the speed layer and consolidating the results.
- This gives end users a complete query on all data, including the most recently added data, to provide a near real-time analytics system.
How Does the Lambda Architecture Work?
One of the important and inevitable fact that we need to acknowledge is that in real-life working environment you might have multiple data sources and systems, and different systems have different velocity to produce data. What Lambda Architecture is trying to do is to provide a holistic view of all different data velocity.
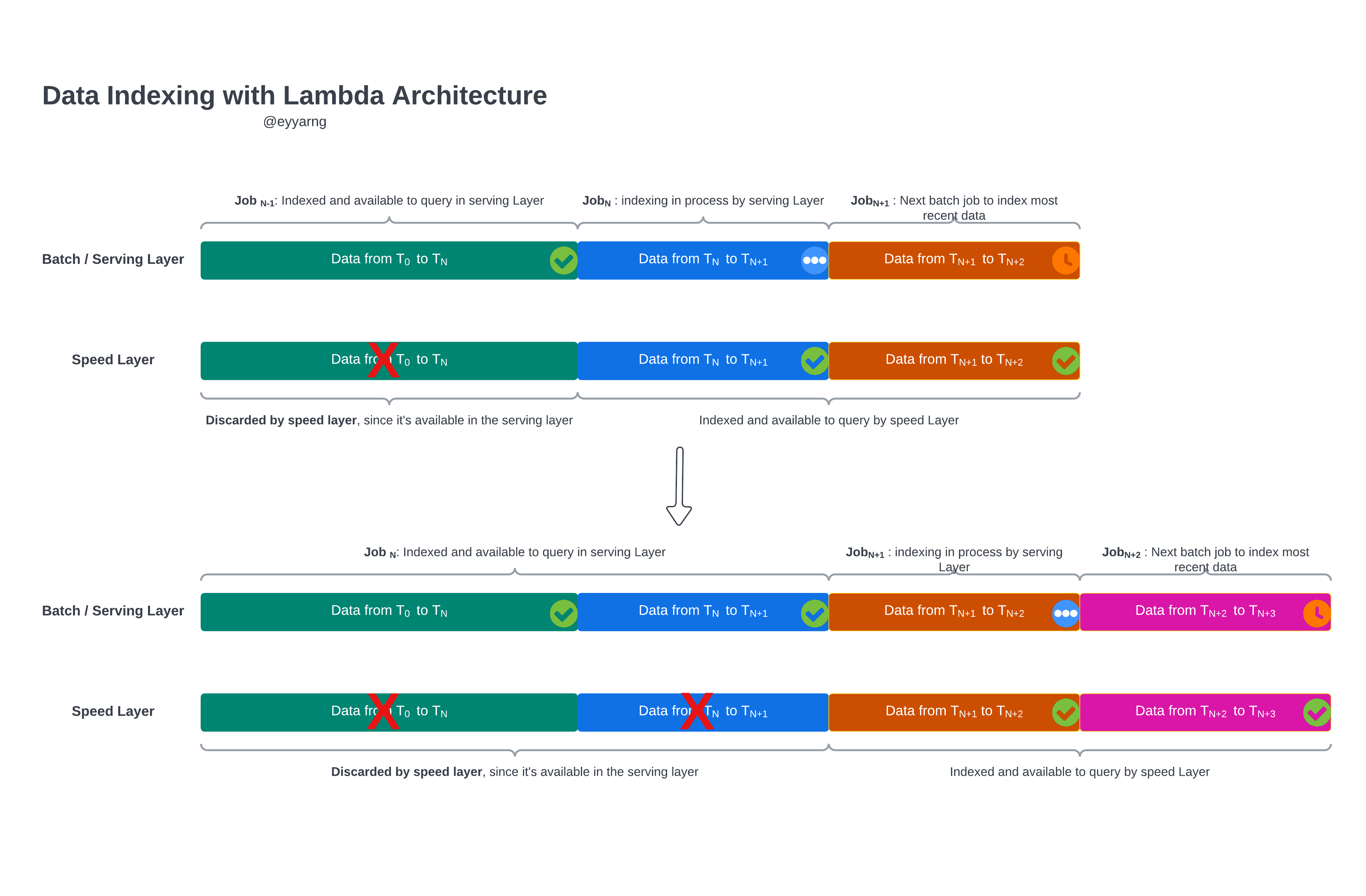
- Data is indexed simultaneously by both the serving layer and speed layer.
- When the serving layer complete a job, it moves to the next batch, and the speed layer discards its copy of the data that the serving layer just indexed.
Benefits of Lambda Architecture
- Latency.
- Data Consistency.
- Scalability.
- Fault Tolerance.
- Human Fault Tolerance.
Kappa Architecture
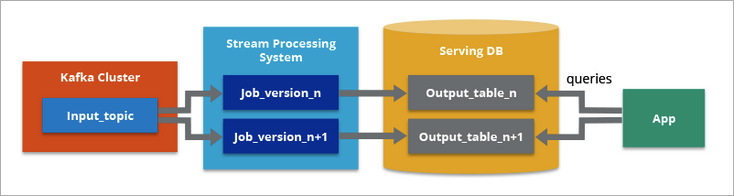
On the other hand, Kappa Architecture is primarily designed for streaming data processing. The main premise behind the Kappa Architecture is you can execute your analytical works on both (near) real-time and batching processing.
Kappa Architecture supports (near) real-time analytics when the data is read and transformed immediately after it is inserted into the messaging engine. This makes recent data quickly available for end user queries.
It also supports historical analytics by reading the stored streaming data from the messaging engine at a later time in a batch manner, to create additional analyzable outputs of more types of analysis.
Lambda vs Kappa
The main difference with Kappa Architecture is that all data is treated as if it were a stream, so the stream processing engine acts as the sole data transformation engine.
Therefore, one major benefit of Kappa Architecture over Lambda Architecture is that it enables you to build your streaming and batch processing system on a single technology. There is no separate technology to handle the batch processing verse (near) real-time processing.
Normally we need a distributed data storage components in Lambda Architecture, it could be either Apache Hadoop, AWS S3, or Azure Blob etc.
One advantage of Lambda Architecture is that much larger data sets (i.e. in petabyte range) can be stored and processed more efficiently in Hadoop for large-scale historical analysis.