Database Scaling is one of the most important topics in System Design . Normally for any large scale application architecture, the database is usually going to be where your performance bottleneck is.
That’s because while most of your application are essentially stateless, so that you can scale them horizontally as much as you need. All the applications will hit the database for retrieving data, or writing new data.
Key Information
Most of the large-scale web application are very read-intensive, usually around 95% read request and 5% write requests.
So in almost of all cases, you want to prioritise and build around the idea that your database will receive a lot more reads than writes.
Basic Scaling Techniques
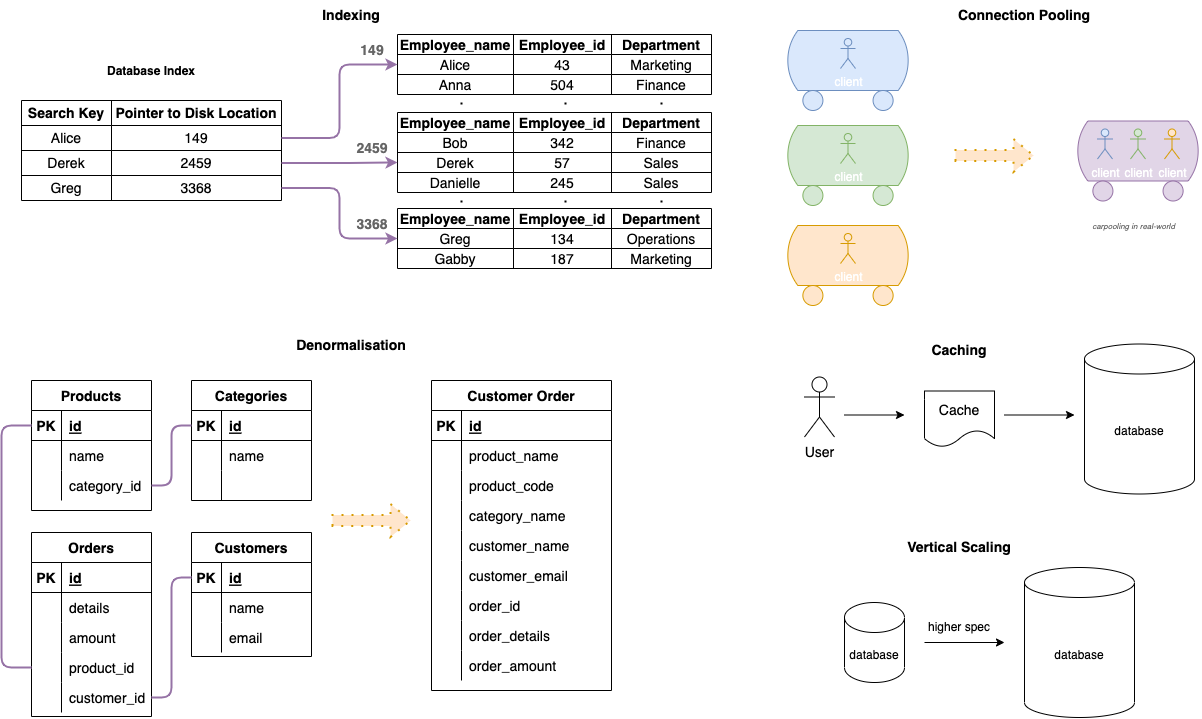
- Indexes.
- index based on column.
- speeds up read performance.
- writes and updates become slightly slower.
- more storage for index.
- Denormalisation.
- add redundant data to tables to reduce joins.
- boosts read performance.
- slow down writes.
- risk inconsistent data across tables.
- code is harder to write.
- Connection Pooling.
- Allow multiple application threads to use same DB connection. (car pooling)
- Saves on overhead of independent database connections.
- Caching
- not directly related to database.
- cache sits in front of database to handle serving content.
- can’t cache everything.
- Vertical Scaling
- Get a bigger server.
- Easiest solution when starting out.
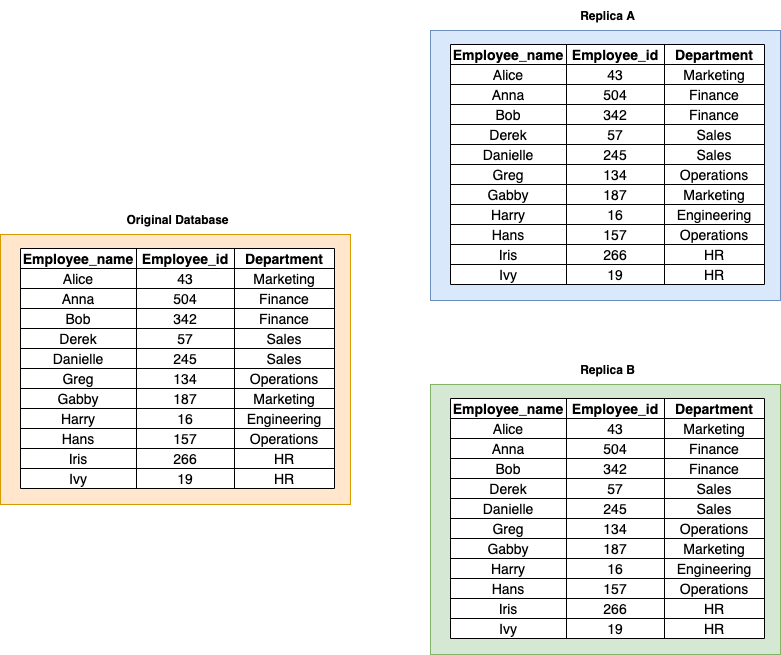
Replication and Partitioning
Read Replicas
- Create replica servers to handle reads.
- Primary server dedicated only to writes.
- Have built-in Fault Tolerance
- Have to handle making sure new data reaches replicas.
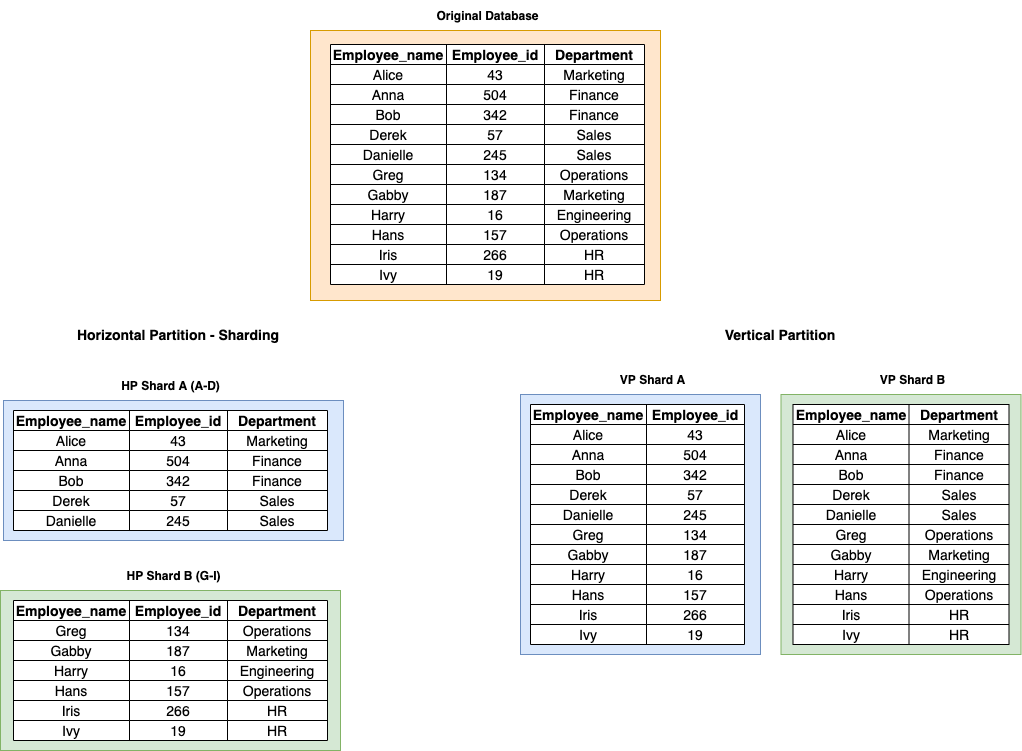
Horizontal Partition - Sharding
- Horizontal Partitioning.
- Schema of table stays the same, but split across multiple DBs.
- Downside - Hotkeys, no joins across shards.
Sharding in Database will separate one table’s rows into multiple different tables, known as partitions. Each partition has exactly the same schema and columns, but also entirely different rows. The data held in each partition is unique and independent.
Database shards exemplify a shared-nothing architecture . This means
- The shards are autonomous.
- They don’t shared any of the same data or computing resources.
Vertical Partitioning
- Divide schema of database into separate tables.
- Generally divide by functionality.
- Best when most data in row isn’t need for most queries.
When to consider NoSQL
So far we pretty much destroyed all the benefits from a relational database
- normalised data.
- strong consistency.
- simple data model.
The reason why you start to consider NoSQL, is not because NoSQL have any magical power, but it’s the fact that you know what you need to sacrificing.
So you probably start everything from a relational database with all the best practices. By the time you ended up scaling you’ve already lost all of that. So the reason you choose a NoSQL database is you know exactly what you need to sacrifice, you know what specifically you need for your application that you can make trade-offs.
So if you are doing something like transactions and banking, you obviously want consistency. But for other company like Google and Facebook, where you don’t need perfect consistency right away, you could make those trade-offs for scale.